Pengantar
 Kecerdasan buatan adalah tentang menggunakan mesin untuk meningkatkan kehidupan dan gaya hidup orang-orang dengan membuat kehidupan duniawi mereka menjadi menarik dan tugas-tugas yang berlebihan menjadi sederhana. AI tidak pernah dianggap sebagai kekuatan yang mendominasi, tetapi sebagai kekuatan pelengkap yang bekerja bersama-sama dengan manusia untuk memecahkan hal-hal yang tidak masuk akal dan membuka jalan bagi evolusi kolektif.
Kecerdasan buatan adalah tentang menggunakan mesin untuk meningkatkan kehidupan dan gaya hidup orang-orang dengan membuat kehidupan duniawi mereka menjadi menarik dan tugas-tugas yang berlebihan menjadi sederhana. AI tidak pernah dianggap sebagai kekuatan yang mendominasi, tetapi sebagai kekuatan pelengkap yang bekerja bersama-sama dengan manusia untuk memecahkan hal-hal yang tidak masuk akal dan membuka jalan bagi evolusi kolektif.
Sampai sekarang, kami menapaki jalan yang benar dengan terobosan signifikan yang terjadi di seluruh industri dengan bantuan AI. Jika Anda mengambil perawatan kesehatan misalnya, sistem AI yang disertai dengan model pembelajaran mesin membantu para ahli memahami kanker dengan lebih baik dan memberikan perawatan untuk itu. Gangguan neurologis dan kekhawatiran seperti PTSD sedang dirawat dengan bantuan AI. Vaksin sedang dikembangkan dengan kecepatan tinggi berkat uji klinis dan simulasi yang didukung AI.
Bukan hanya perawatan kesehatan, setiap industri atau segmen yang disentuh AI sedang mengalami revolusi. Kendaraan otonom, toko swalayan pintar, perangkat yang dapat dikenakan seperti FitBit, dan bahkan kamera ponsel cerdas kami mampu menangkap gambar wajah kami yang lebih baik dengan AI.
Berkat inovasi yang terjadi di ruang AI, perusahaan menerobos spektrum dengan berbagai kasus penggunaan dan solusi. Karena itu, pasar AI global diperkirakan akan mencapai nilai pasar sekitar $267 miliar pada akhir tahun 2027. Selain itu, sekitar 37% bisnis di luar sana telah menerapkan solusi AI ke dalam proses dan produk mereka.
Lebih menarik lagi, hampir 77% produk dan layanan yang kami gunakan saat ini didukung oleh AI. Dengan konsep teknologi yang meningkat secara signifikan di seluruh vertikal, bagaimana bisnis berhasil melakukan hal yang mustahil dengan AI?

 Bagaimana perangkat sesederhana jam tangan secara akurat memprediksi serangan jantung pada manusia? Bagaimana mungkin mobil dan mobil yang selalu membutuhkan pengemudi tiba-tiba kehilangan pengemudi di jalan?
Bagaimana perangkat sesederhana jam tangan secara akurat memprediksi serangan jantung pada manusia? Bagaimana mungkin mobil dan mobil yang selalu membutuhkan pengemudi tiba-tiba kehilangan pengemudi di jalan?
Bagaimana chatbots membuat kita percaya bahwa kita sedang berbicara dengan manusia lain di sisi lain?
Jika Anda mengamati jawaban untuk setiap pertanyaan, itu hanya bermuara pada satu elemen – DATA. Data berada di pusat semua operasi dan proses khusus AI. Ini adalah data yang membantu mesin memahami konsep, memproses input, dan memberikan hasil yang akurat.
Semua solusi AI utama yang ada di luar sana adalah produk dari proses penting yang kami sebut pengumpulan data atau akuisisi data atau data pelatihan AI.
Panduan ekstensif ini adalah tentang membantu Anda memahami apa itu dan mengapa itu penting.
Apa itu Pengumpulan Data AI?
Mesin tidak memiliki pikirannya sendiri. Ketiadaan konsep abstrak ini membuat mereka tidak memiliki pendapat, fakta dan kemampuan seperti penalaran, kognisi dan lainnya. Mereka hanyalah kotak atau perangkat tak bergerak yang menempati ruang. Untuk mengubahnya menjadi media yang kuat, Anda memerlukan algoritme dan yang lebih penting data.
 Algoritma yang dikembangkan membutuhkan sesuatu untuk dikerjakan dan diproses dan sesuatu itu adalah data yang relevan, kontekstual dan terkini. Proses pengumpulan data tersebut untuk mesin untuk melayani tujuan yang dimaksudkan disebut pengumpulan data AI.
Algoritma yang dikembangkan membutuhkan sesuatu untuk dikerjakan dan diproses dan sesuatu itu adalah data yang relevan, kontekstual dan terkini. Proses pengumpulan data tersebut untuk mesin untuk melayani tujuan yang dimaksudkan disebut pengumpulan data AI.
Setiap produk atau solusi berkemampuan AI yang kami gunakan saat ini dan hasil yang mereka tawarkan berasal dari pelatihan, pengembangan, dan pengoptimalan selama bertahun-tahun. Dari perangkat yang menawarkan rute navigasi hingga sistem kompleks yang memprediksi kegagalan peralatan beberapa hari sebelumnya, setiap entitas telah melalui bertahun-tahun pelatihan AI untuk dapat memberikan hasil secara akurat.
pengumpulan data AI adalah langkah awal dalam proses pengembangan AI yang sejak awal menentukan seberapa efektif dan efisien sistem AI nantinya. Ini adalah proses mendapatkan kumpulan data yang relevan dari berbagai sumber yang akan membantu model AI memproses detail dengan lebih baik dan menghasilkan hasil yang berarti.




Bagaimana cara Mengumpulkan data untuk Pembelajaran Mesin?
 Di sinilah segalanya mulai menjadi sedikit rumit. Sejak awal, sepertinya Anda memiliki solusi untuk masalah dunia nyata dalam pikiran, Anda tahu AI akan menjadi cara yang ideal untuk melakukannya dan Anda telah mengembangkan model Anda. Tetapi sekarang, Anda berada dalam fase penting di mana Anda perlu memulai proses pelatihan AI Anda. Anda memerlukan banyak data pelatihan AI untuk membuat model Anda mempelajari konsep dan memberikan hasil. Anda juga memerlukan data validasi untuk menguji hasil dan mengoptimalkan algoritme Anda.
Di sinilah segalanya mulai menjadi sedikit rumit. Sejak awal, sepertinya Anda memiliki solusi untuk masalah dunia nyata dalam pikiran, Anda tahu AI akan menjadi cara yang ideal untuk melakukannya dan Anda telah mengembangkan model Anda. Tetapi sekarang, Anda berada dalam fase penting di mana Anda perlu memulai proses pelatihan AI Anda. Anda memerlukan banyak data pelatihan AI untuk membuat model Anda mempelajari konsep dan memberikan hasil. Anda juga memerlukan data validasi untuk menguji hasil dan mengoptimalkan algoritme Anda.
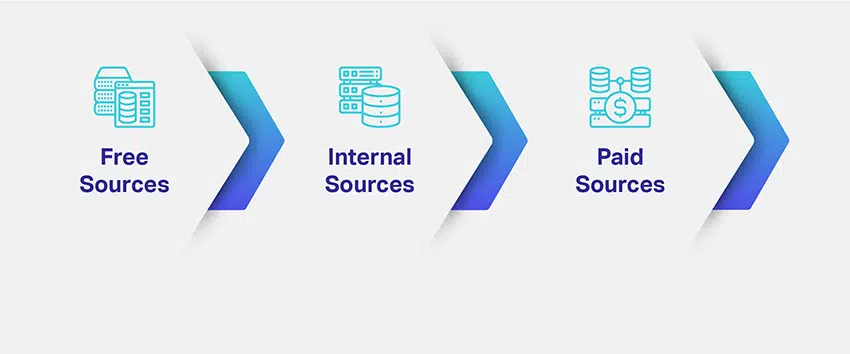
Jadi, bagaimana Anda sumber data Anda? Data apa yang Anda butuhkan dan berapa banyak? Apa sajakah berbagai sumber untuk mengambil data yang relevan?
Perusahaan menilai ceruk dan tujuan model ML mereka dan memetakan cara potensial untuk mendapatkan kumpulan data yang relevan. Mendefinisikan tipe data yang dibutuhkan memecahkan sebagian besar perhatian Anda pada sumber data. Untuk memberi Anda ide yang lebih baik, ada berbagai saluran, jalan, sumber, atau media untuk pengumpulan data:
Bagaimana data buruk memengaruhi ambisi AI Anda?
Kami mencantumkan tiga sumber data paling umum dengan alasan bahwa Anda akan memiliki ide tentang cara mendekati pengumpulan dan sumber data. Namun, pada titik ini, penting juga untuk memahami bahwa keputusan Anda selalu dapat menentukan nasib solusi AI Anda.
Mirip dengan bagaimana data pelatihan AI berkualitas tinggi dapat membantu model Anda memberikan hasil yang akurat dan tepat waktu, data pelatihan yang buruk juga dapat merusak model AI Anda, mengubah hasil, menimbulkan bias, dan menawarkan konsekuensi lain yang tidak diinginkan.
Tapi mengapa ini terjadi? Bukankah ada data yang seharusnya melatih dan mengoptimalkan model AI Anda? Jujur, tidak. Mari kita memahami ini lebih lanjut.
Data Buruk – Apa Itu?
 Data buruk adalah data yang tidak relevan, tidak benar, tidak lengkap, atau bias. Berkat strategi pengumpulan data yang tidak jelas, sebagian besar ilmuwan data dan ahli anotasi dipaksa untuk bekerja pada data yang buruk.
Data buruk adalah data yang tidak relevan, tidak benar, tidak lengkap, atau bias. Berkat strategi pengumpulan data yang tidak jelas, sebagian besar ilmuwan data dan ahli anotasi dipaksa untuk bekerja pada data yang buruk.
Perbedaan antara data tidak terstruktur dan data buruk adalah bahwa wawasan dalam data tidak terstruktur ada di mana-mana. Tetapi pada intinya, mereka bisa berguna terlepas dari itu. Dengan menghabiskan waktu tambahan, ilmuwan data masih dapat mengekstrak informasi yang relevan dari kumpulan data yang tidak terstruktur. Namun, tidak demikian halnya dengan data yang buruk. Kumpulan data ini tidak berisi/wawasan terbatas atau informasi yang berharga atau relevan dengan proyek AI Anda atau tujuan pelatihannya.
Jadi, ketika Anda mengambil sumber dataset Anda dari sumber daya gratis atau telah menetapkan titik kontak data internal yang longgar, kemungkinan besar Anda akan mengunduh atau menghasilkan data yang buruk. Ketika ilmuwan Anda mengerjakan data yang buruk, Anda tidak hanya membuang-buang waktu, tetapi juga mendorong peluncuran produk Anda.
Jika Anda masih tidak jelas tentang apa yang dapat dilakukan data buruk terhadap ambisi Anda, berikut adalah daftar singkatnya:
- Anda menghabiskan waktu berjam-jam untuk mencari data yang buruk dan membuang-buang waktu, tenaga, dan uang untuk sumber daya.
- Data yang buruk dapat membawa Anda ke masalah hukum, jika tidak diketahui dan dapat menurunkan efisiensi AI Anda
model. - Saat Anda melatih produk Anda tentang data buruk secara langsung, itu memengaruhi pengalaman pengguna
- Data yang buruk dapat membuat hasil dan kesimpulan menjadi bias, yang selanjutnya dapat menimbulkan reaksi balik.
Jadi, jika Anda bertanya-tanya apakah ada solusi untuk ini, sebenarnya ada.
Penyedia Data Pelatihan AI untuk menyelamatkan
 Salah satu solusi dasar adalah mencari vendor data (sumber berbayar). Penyedia data pelatihan AI memastikan apa yang Anda terima akurat dan relevan dan Anda memiliki kumpulan data yang dikirimkan kepada Anda dalam bentuk terstruktur. Anda tidak perlu repot berpindah dari satu portal ke portal lainnya untuk mencari kumpulan data.
Salah satu solusi dasar adalah mencari vendor data (sumber berbayar). Penyedia data pelatihan AI memastikan apa yang Anda terima akurat dan relevan dan Anda memiliki kumpulan data yang dikirimkan kepada Anda dalam bentuk terstruktur. Anda tidak perlu repot berpindah dari satu portal ke portal lainnya untuk mencari kumpulan data.
Yang harus Anda lakukan adalah mengambil data dan melatih model AI Anda untuk kesempurnaan. Dengan demikian, kami yakin pertanyaan Anda selanjutnya adalah tentang biaya yang terkait dengan kolaborasi dengan vendor data. Kami memahami bahwa beberapa dari Anda sudah bekerja dengan anggaran mental dan ke sanalah kami menuju selanjutnya.
Faktor-faktor yang perlu dipertimbangkan ketika membuat Anggaran yang efektif untuk Proyek Pengumpulan Data Anda
Pelatihan AI adalah pendekatan sistematis dan itulah sebabnya penganggaran menjadi bagian integral darinya. Faktor-faktor seperti RoI, akurasi hasil, metodologi pelatihan, dan lainnya harus dipertimbangkan sebelum menginvestasikan sejumlah besar uang ke dalam pengembangan AI. Banyak manajer proyek atau pemilik bisnis gagal pada tahap ini. Mereka membuat keputusan tergesa-gesa yang membawa perubahan yang tidak dapat diubah dalam proses pengembangan produk mereka, yang pada akhirnya memaksa mereka untuk membelanjakan lebih banyak.
Namun, bagian ini akan memberi Anda wawasan yang tepat. Saat Anda duduk untuk mengerjakan anggaran untuk pelatihan AI, tiga hal atau faktor tidak dapat dihindari.

Mari kita lihat masing-masing secara detail.
Volume data yang Anda butuhkan
Kami telah mengatakan selama ini bahwa efisiensi dan akurasi model AI Anda bergantung pada seberapa banyak ia dilatih. Artinya semakin banyak volume dataset, semakin banyak pembelajarannya. Tapi ini sangat tidak jelas. Untuk memberikan angka pada gagasan ini, Dimensional Research menerbitkan sebuah laporan yang mengungkapkan bahwa bisnis membutuhkan minimal 100,000 kumpulan data sampel untuk melatih model AI mereka.
Dengan 100,000 kumpulan data, yang kami maksud adalah 100,000 kumpulan data yang berkualitas dan relevan. Kumpulan data ini harus memiliki semua atribut penting, anotasi, dan wawasan yang diperlukan untuk algoritme dan model pembelajaran mesin Anda untuk memproses informasi dan menjalankan tugas yang diinginkan.
Dengan ini adalah aturan umum, mari kita pahami lebih jauh bahwa volume data yang Anda butuhkan juga bergantung pada faktor rumit lainnya yang merupakan kasus penggunaan bisnis Anda. Apa yang ingin Anda lakukan dengan produk atau solusi Anda juga menentukan berapa banyak data yang Anda butuhkan. Misalnya, bisnis yang membangun mesin rekomendasi akan memiliki persyaratan volume data yang berbeda dari perusahaan yang membuat chatbot.
Strategi Harga Data
Setelah selesai menyelesaikan berapa banyak data yang sebenarnya Anda butuhkan, selanjutnya Anda perlu mengerjakan strategi penetapan harga data. Ini, secara sederhana, berarti bagaimana Anda akan membayar untuk kumpulan data yang Anda peroleh atau hasilkan.
Secara umum, ini adalah strategi penetapan harga konvensional yang diikuti di pasar:
| Tipe data | Strategi Penentuan Harga |
|---|---|
| Harga per file gambar tunggal | |
| Harga per detik, menit, satu jam, atau bingkai individu | |
| Harga per detik, menit, atau jam | |
| Harga per kata atau kalimat |
Tapi tunggu. Ini lagi-lagi aturan praktis. Biaya aktual pengadaan kumpulan data juga bergantung pada faktor-faktor seperti:
- Segmen pasar, demografi, atau geografi yang unik dari mana kumpulan data harus bersumber
- Kerumitan kasus penggunaan Anda
- Berapa banyak data yang Anda butuhkan?
- Waktu Anda ke pasar
- Persyaratan yang disesuaikan dan lainnya
Jika Anda amati, Anda akan tahu bahwa biaya untuk memperoleh gambar dalam jumlah besar untuk proyek AI Anda bisa lebih murah, tetapi jika Anda memiliki terlalu banyak spesifikasi, harganya bisa naik.
Strategi Sumber Anda
Ini rumit. Seperti yang Anda lihat, ada berbagai cara untuk menghasilkan atau sumber data untuk model AI Anda. Akal sehat akan menentukan bahwa sumber daya gratis adalah yang terbaik karena Anda dapat mengunduh volume kumpulan data yang diperlukan secara gratis tanpa komplikasi.
Saat ini, tampaknya sumber berbayar juga terlalu mahal. Tapi di sinilah lapisan komplikasi akan ditambahkan. Saat Anda mengambil sumber dataset dari sumber daya gratis, Anda menghabiskan lebih banyak waktu dan upaya untuk membersihkan dataset Anda, mengompilasinya ke dalam format khusus bisnis Anda dan kemudian membuat anotasi satu per satu. Anda mengeluarkan biaya operasional dalam prosesnya.
Dengan sumber berbayar, pembayaran dilakukan satu kali dan Anda juga mendapatkan set data siap pakai mesin pada waktu yang Anda butuhkan. Efektivitas biaya sangat subjektif di sini. Jika Anda merasa mampu menghabiskan waktu untuk membuat anotasi set data gratis, Anda dapat menganggarkannya dengan tepat. Dan jika Anda yakin persaingan Anda ketat dan dengan waktu terbatas ke pasar, Anda dapat menciptakan efek riak di pasar, Anda harus memilih sumber berbayar.
Penganggaran adalah tentang memecah secara spesifik dan dengan jelas mendefinisikan setiap fragmen. Ketiga faktor ini akan menjadi peta jalan untuk proses penganggaran pelatihan AI Anda di masa mendatang.
Apakah Anda menghemat pengeluaran dengan Akuisisi Data internal?
 Saat membuat anggaran, kami mempelajari bagaimana sumber daya gratis memaksa Anda untuk membelanjakan lebih banyak dalam jangka panjang. Pada saat itu, Anda akan secara otomatis bertanya-tanya tentang efektivitas biaya dari proses akuisisi data internal.
Saat membuat anggaran, kami mempelajari bagaimana sumber daya gratis memaksa Anda untuk membelanjakan lebih banyak dalam jangka panjang. Pada saat itu, Anda akan secara otomatis bertanya-tanya tentang efektivitas biaya dari proses akuisisi data internal.
Kami tahu bahwa Anda masih ragu tentang sumber berbayar dan itulah sebabnya bagian ini akan menghapus keraguan Anda tentang hal itu dan menjelaskan biaya tersembunyi yang terlibat dalam pembuatan data internal.
Apakah Akuisisi Data In-house Mahal?
Ya itu!
Sekarang, inilah tanggapan yang rumit. Pengeluaran adalah segala sesuatu yang Anda belanjakan. Saat mendiskusikan sumber daya gratis, kami mengungkapkan bahwa Anda menghabiskan uang, waktu & upaya dalam proses. Ini juga berlaku untuk akuisisi data internal.
 Karena fakta bahwa Anda memiliki titik sentuh atau corong data yang ditentukan khusus, itu tidak berarti Anda akan memilikinya set data siap mesin pada akhirnya. Data yang Anda hasilkan sebagian besar masih mentah dan tidak terstruktur. Anda mungkin memiliki semua data yang Anda butuhkan di satu tempat tetapi isi data tersebut akan ada di mana-mana.
Karena fakta bahwa Anda memiliki titik sentuh atau corong data yang ditentukan khusus, itu tidak berarti Anda akan memilikinya set data siap mesin pada akhirnya. Data yang Anda hasilkan sebagian besar masih mentah dan tidak terstruktur. Anda mungkin memiliki semua data yang Anda butuhkan di satu tempat tetapi isi data tersebut akan ada di mana-mana.
Pada akhirnya, Anda akan menghabiskan uang untuk membayar karyawan, ilmuwan data, annotator, profesional jaminan kualitas, dan banyak lagi. Anda juga akan menghabiskan langganan untuk alat anotasi dan
pemeliharaan CMS, CRM dan biaya infrastruktur lainnya.
Selain itu, kumpulan data pasti memiliki masalah bias dan akurasi, yang Anda perlukan untuk menyortirnya secara manual. Dan jika Anda memiliki masalah atrisi dalam tim data pelatihan AI Anda, Anda harus mengeluarkan biaya untuk merekrut anggota baru, mengarahkan mereka ke proses Anda, melatih mereka untuk menggunakan alat Anda, dan banyak lagi.
Anda akhirnya akan menghabiskan lebih dari apa yang akhirnya akan Anda hasilkan dalam jangka panjang. Ada juga biaya anotasi. Pada titik waktu tertentu, total biaya yang dikeluarkan untuk bekerja dengan data internal adalah:
Biaya yang Dikenakan = Jumlah Annotator * Biaya per annotator + Biaya Platform
Jika kalender pelatihan AI Anda dijadwalkan selama berbulan-bulan, bayangkan biaya yang akan Anda keluarkan secara konsisten. Jadi, apakah ini solusi ideal untuk masalah akuisisi data atau adakah alternatif lain?
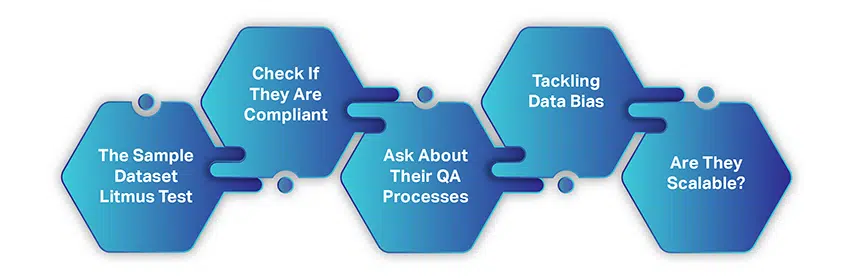
Bagaimana memilih Perusahaan Pengumpulan Data AI yang tepat
Memilih perusahaan pengumpulan data AI tidak serumit atau memakan waktu seperti mengumpulkan data dari sumber daya gratis. Hanya ada beberapa faktor sederhana yang perlu Anda pertimbangkan dan kemudian berjabat tangan untuk sebuah kolaborasi.
Saat Anda mulai mencari vendor data, kami berasumsi bahwa Anda telah mengikuti dan mempertimbangkan apa pun yang telah kami diskusikan sejauh ini. Namun, inilah rekap singkatnya:
- Anda memiliki kasus penggunaan yang terdefinisi dengan baik dalam pikiran
- Segmen pasar dan persyaratan data Anda ditetapkan dengan jelas
- Penganggaran Anda tepat sasaran
- Dan Anda memiliki gambaran tentang volume data yang Anda butuhkan
Dengan item ini dicentang, mari kita pahami bagaimana Anda dapat mencari penyedia layanan data pelatihan yang ideal.