
Kecerdasan Buatan dan Big Data memiliki potensi untuk menemukan solusi untuk masalah global sambil memprioritaskan masalah lokal dan mengubah dunia dengan banyak cara. AI menghadirkan solusi untuk semua – dan di semua pengaturan, dari rumah hingga tempat kerja. komputer AI, dengan Pembelajaran mesin pelatihan, dapat mensimulasikan perilaku cerdas dan percakapan secara otomatis namun personal.
Namun, AI menghadapi masalah inklusi dan seringkali bias. Untungnya, fokus pada etika kecerdasan buatan dapat mengantarkan kemungkinan yang lebih baru dalam hal diversifikasi dan inklusi dengan menghilangkan bias yang tidak disadari melalui beragam data pelatihan.
Pentingnya keragaman dalam data pelatihan AI
 Keanekaragaman dan kualitas data pelatihan terkait karena yang satu memengaruhi yang lain dan memengaruhi hasil solusi AI. Keberhasilan solusi AI bergantung pada data yang beragam itu dilatih. Keanekaragaman data mencegah AI dari overfitting – artinya model hanya bekerja atau belajar dari data yang digunakan untuk berlatih. Dengan overfitting, model AI tidak dapat memberikan hasil saat diuji pada data yang tidak digunakan dalam pelatihan.
Keanekaragaman dan kualitas data pelatihan terkait karena yang satu memengaruhi yang lain dan memengaruhi hasil solusi AI. Keberhasilan solusi AI bergantung pada data yang beragam itu dilatih. Keanekaragaman data mencegah AI dari overfitting – artinya model hanya bekerja atau belajar dari data yang digunakan untuk berlatih. Dengan overfitting, model AI tidak dapat memberikan hasil saat diuji pada data yang tidak digunakan dalam pelatihan.
Kondisi pelatihan AI Saat Ini data
Ketidaksetaraan atau kurangnya keragaman dalam data akan mengarah pada solusi AI yang tidak adil, tidak etis, dan tidak inklusif yang dapat memperdalam diskriminasi. Tapi bagaimana dan mengapa keragaman data terkait dengan solusi AI?
Representasi yang tidak sama dari semua kelas menyebabkan kesalahan identifikasi wajah – salah satu kasus penting adalah Foto Google yang mengklasifikasikan pasangan kulit hitam sebagai 'gorila'. Dan Meta meminta pengguna menonton video pria kulit hitam apakah pengguna ingin 'melanjutkan menonton video primata.'
Misalnya, klasifikasi etnis atau ras minoritas yang tidak akurat atau tidak tepat, terutama di chatbot, dapat mengakibatkan prasangka dalam sistem pelatihan AI. Menurut laporan 2019 tentang Sistem Diskriminasi – Jenis Kelamin, Ras, Kekuasaan dalam AI, lebih dari 80% guru AI adalah laki-laki; peneliti AI wanita di FB hanya terdiri dari 15% dan 10% di Google.
Dampak Beragam Data Pelatihan pada Kinerja AI
 Meninggalkan grup dan komunitas tertentu dari representasi data dapat menyebabkan algoritme miring.
Meninggalkan grup dan komunitas tertentu dari representasi data dapat menyebabkan algoritme miring.
Bias data sering kali secara tidak sengaja dimasukkan ke dalam sistem data – dengan mengambil sampel ras atau kelompok tertentu. Saat sistem pengenalan wajah dilatih pada beragam wajah, ini membantu model mengidentifikasi fitur spesifik, seperti posisi organ wajah dan variasi warna.
Hasil lain dari frekuensi label yang tidak seimbang adalah bahwa sistem mungkin menganggap minoritas sebagai anomali ketika ditekan untuk menghasilkan keluaran dalam waktu singkat.
Mencapai Keanekaragaman dalam Data Pelatihan AI
Di sisi lain, menghasilkan kumpulan data yang beragam juga merupakan tantangan. Kurangnya data pada kelas-kelas tertentu dapat menyebabkan kurangnya representasi. Ini dapat dikurangi dengan membuat tim pengembang AI lebih beragam sehubungan dengan keterampilan, etnis, ras, jenis kelamin, disiplin, dan lainnya. Selain itu, Cara ideal untuk mengatasi masalah keragaman data di AI adalah dengan menghadapinya dari awal alih-alih mencoba memperbaiki apa yang telah dilakukan – menanamkan keragaman pada tahap pengumpulan dan kurasi data.
Terlepas dari hype seputar AI, itu tetap bergantung pada data yang dikumpulkan, dipilih, dan dilatih oleh manusia. Bias bawaan pada manusia akan tercermin dalam data yang dikumpulkan oleh mereka, dan bias tak sadar ini juga merayap ke dalam model ML.
Langkah-langkah untuk mengumpulkan dan menyusun beragam data pelatihan
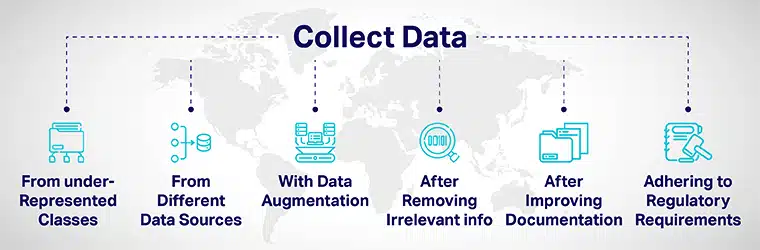
Keragaman data dapat dicapai dengan:
- Tambahkan lebih banyak data dengan hati-hati dari kelas yang kurang terwakili dan tampilkan model Anda ke berbagai titik data.
- Dengan mengumpulkan data dari berbagai sumber data.
- Dengan augmentasi data atau memanipulasi kumpulan data secara artifisial untuk menambah/menyertakan titik data baru yang sangat berbeda dari titik data asli.
- Saat merekrut pelamar untuk proses pengembangan AI, hapus semua informasi yang tidak relevan dengan pekerjaan dari aplikasi.
- Meningkatkan transparansi dan akuntabilitas dengan meningkatkan dokumentasi pengembangan dan evaluasi model.
- Memperkenalkan peraturan untuk membangun keragaman dan inklusivitas dalam AI sistem dari tingkat akar rumput. Berbagai pemerintah telah mengembangkan pedoman untuk memastikan keragaman dan mengurangi bias AI yang dapat memberikan hasil yang tidak adil.
[ Baca juga: Pelajari Lebih Lanjut Tentang Proses Pengumpulan Data Pelatihan AI ]
Kesimpulan
Saat ini, hanya beberapa perusahaan teknologi besar dan pusat pembelajaran yang secara eksklusif terlibat dalam pengembangan solusi AI. Ruang elit ini penuh dengan eksklusi, diskriminasi, dan bias. Namun, ini adalah ruang di mana AI sedang dikembangkan, dan logika di balik sistem AI canggih ini penuh dengan bias, diskriminasi, dan pengucilan yang sama yang ditanggung oleh kelompok yang kurang terwakili.
Saat membahas keragaman dan non-diskriminasi, penting untuk mempertanyakan orang-orang yang diuntungkan dan dirugikan. Kita juga harus melihat siapa yang dirugikan – dengan memaksakan gagasan tentang orang 'normal', AI berpotensi membahayakan 'orang lain'.
Membahas keragaman dalam data AI tanpa mengakui hubungan kekuasaan, kesetaraan, dan keadilan tidak akan menunjukkan gambaran yang lebih besar. Untuk memahami sepenuhnya ruang lingkup keragaman dalam data pelatihan AI dan bagaimana manusia dan AI dapat bersama-sama memitigasi krisis ini, menjangkau para insinyur di Shaip. Kami memiliki beragam insinyur AI yang dapat memberikan data yang dinamis dan beragam untuk solusi AI Anda.


