

Apa itu Model Bahasa Besar?
Model Bahasa Besar (LLM) adalah sistem kecerdasan buatan (AI) canggih yang dirancang untuk memproses, memahami, dan menghasilkan teks mirip manusia. Mereka didasarkan pada teknik pembelajaran mendalam dan dilatih pada kumpulan data besar, biasanya berisi miliaran kata dari berbagai sumber seperti situs web, buku, dan artikel. Pelatihan ekstensif ini memungkinkan LLM untuk memahami nuansa bahasa, tata bahasa, konteks, dan bahkan beberapa aspek pengetahuan umum.
Beberapa LLM populer, seperti GPT-3 OpenAI, menggunakan jenis jaringan saraf yang disebut transformator, yang memungkinkan mereka menangani tugas bahasa yang kompleks dengan kemampuan luar biasa. Model ini dapat melakukan berbagai tugas, seperti:
- Menjawab pertanyaan
- Meringkas teks
- Menerjemahkan bahasa
- Menghasilkan konten
- Bahkan terlibat dalam percakapan interaktif dengan pengguna
Saat LLM terus berkembang, mereka memiliki potensi besar untuk meningkatkan dan mengotomatiskan berbagai aplikasi di seluruh industri, mulai dari layanan pelanggan dan pembuatan konten hingga pendidikan dan penelitian. Namun, mereka juga menimbulkan masalah etika dan sosial, seperti perilaku bias atau penyalahgunaan, yang perlu ditangani seiring dengan kemajuan teknologi.

Contoh Populer Model Bahasa Besar
Berikut adalah beberapa contoh LLM terkemuka yang digunakan secara luas di vertikal industri yang berbeda:
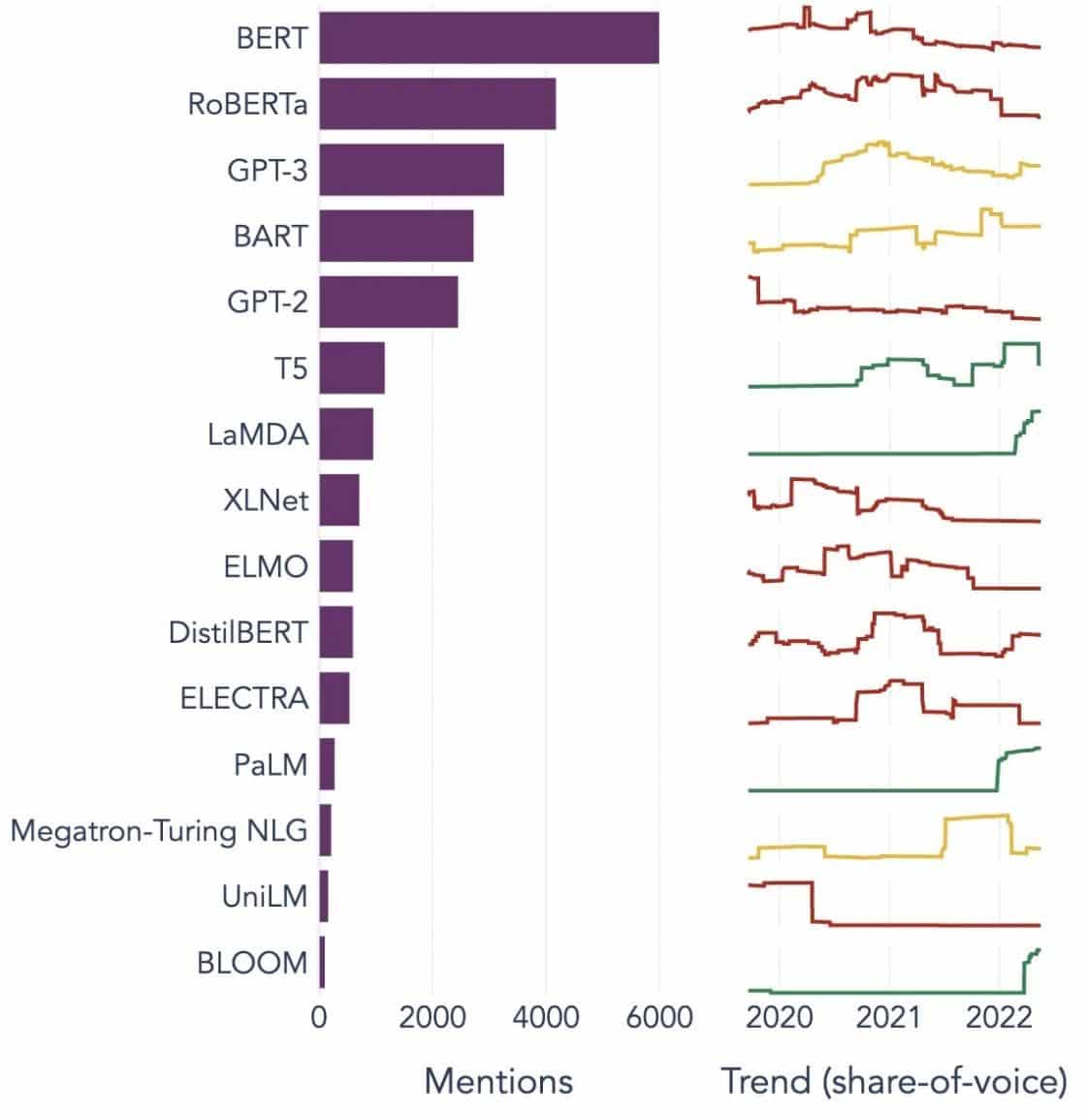
Sumber Gambar: Menuju Ilmu data
Bagaimana model LLM dilatih?
Melatih model bahasa besar (LLM) adalah suatu prestasi yang melibatkan beberapa langkah penting. Berikut adalah ikhtisar proses langkah demi langkah yang disederhanakan:
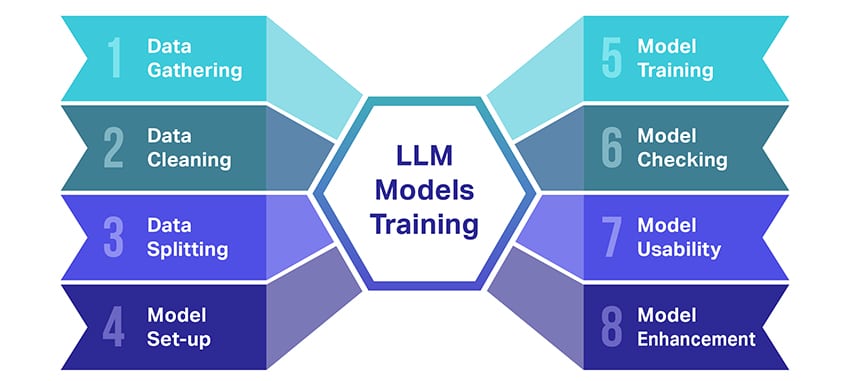
- Mengumpulkan Data Teks: Melatih LLM dimulai dengan pengumpulan sejumlah besar data teks. Data ini bisa berasal dari buku, website, artikel, atau platform media sosial. Tujuannya adalah untuk menangkap keanekaragaman bahasa manusia yang kaya.
- Membersihkan Data: Data teks mentah tersebut kemudian dirapikan dalam proses yang disebut preprocessing. Ini termasuk tugas-tugas seperti menghapus karakter yang tidak diinginkan, memecah teks menjadi bagian-bagian kecil yang disebut token, dan memasukkan semuanya ke dalam format yang dapat digunakan oleh model.
- Memisahkan Data: Selanjutnya, data bersih dibagi menjadi dua set. Satu set, data pelatihan, akan digunakan untuk melatih model. Set lainnya, data validasi, akan digunakan nanti untuk menguji performa model.
- Menyiapkan Model: Struktur LLM, yang dikenal sebagai arsitektur, kemudian didefinisikan. Ini melibatkan pemilihan jenis jaringan saraf dan memutuskan berbagai parameter, seperti jumlah lapisan dan unit tersembunyi di dalam jaringan.
- Melatih Model: Pelatihan yang sebenarnya sekarang dimulai. Model LLM belajar dengan melihat data pelatihan, membuat prediksi berdasarkan apa yang telah dipelajari sejauh ini, dan kemudian menyesuaikan parameter internalnya untuk mengurangi perbedaan antara prediksinya dan data sebenarnya.
- Memeriksa Model: Pembelajaran model LLM diperiksa menggunakan data validasi. Ini membantu untuk melihat seberapa baik kinerja model dan mengubah pengaturan model untuk kinerja yang lebih baik.
- Menggunakan Model: Setelah pelatihan dan evaluasi, model LLM siap digunakan. Sekarang dapat diintegrasikan ke dalam aplikasi atau sistem di mana ia akan menghasilkan teks berdasarkan input baru yang diberikan.
- Memperbaiki Model: Akhirnya, selalu ada ruang untuk perbaikan. Model LLM dapat disempurnakan lebih lanjut dari waktu ke waktu, menggunakan data yang diperbarui atau menyesuaikan pengaturan berdasarkan umpan balik dan penggunaan di dunia nyata.
Ingat, proses ini memerlukan sumber daya komputasi yang signifikan, seperti unit pemrosesan yang kuat dan penyimpanan yang besar, serta pengetahuan khusus dalam pembelajaran mesin. Itu sebabnya biasanya dilakukan oleh organisasi atau perusahaan penelitian khusus dengan akses ke infrastruktur dan keahlian yang diperlukan.
Apakah LLM Mengandalkan Pembelajaran yang Diawasi atau Tidak Diawasi?
Model bahasa besar biasanya dilatih menggunakan metode yang disebut pembelajaran terawasi. Secara sederhana, ini berarti mereka belajar dari contoh yang menunjukkan kepada mereka jawaban yang benar.
 Bayangkan Anda sedang mengajari seorang anak kata-kata dengan menunjukkan gambar-gambar kepada mereka. Anda menunjukkan gambar kucing dan berkata "kucing", dan mereka belajar mengasosiasikan gambar itu dengan kata tersebut. Begitulah cara kerja pembelajaran yang diawasi. Model diberi banyak teks ("gambar") dan keluaran yang sesuai ("kata-kata"), dan ia belajar untuk mencocokkannya.
Bayangkan Anda sedang mengajari seorang anak kata-kata dengan menunjukkan gambar-gambar kepada mereka. Anda menunjukkan gambar kucing dan berkata "kucing", dan mereka belajar mengasosiasikan gambar itu dengan kata tersebut. Begitulah cara kerja pembelajaran yang diawasi. Model diberi banyak teks ("gambar") dan keluaran yang sesuai ("kata-kata"), dan ia belajar untuk mencocokkannya.
Jadi, jika Anda memberi kalimat kepada LLM, LLM mencoba memprediksi kata atau frasa berikutnya berdasarkan apa yang telah dipelajari dari contoh. Dengan cara ini, ia mempelajari cara menghasilkan teks yang masuk akal dan sesuai dengan konteksnya.
Konon, terkadang LLM juga menggunakan sedikit pembelajaran tanpa pengawasan. Ini seperti membiarkan anak menjelajahi ruangan yang penuh dengan mainan yang berbeda dan mempelajarinya sendiri. Model melihat data yang tidak berlabel, pola pembelajaran, dan struktur tanpa diberi tahu jawaban yang "benar".
Pembelajaran terawasi menggunakan data yang diberi label dengan masukan dan keluaran, berbeda dengan pembelajaran tanpa pengawasan, yang tidak menggunakan data keluaran berlabel.
Singkatnya, LLM terutama dilatih menggunakan pembelajaran yang diawasi, tetapi mereka juga dapat menggunakan pembelajaran yang tidak diawasi untuk meningkatkan kemampuannya, seperti untuk analisis eksplorasi dan pengurangan dimensi.
Berapa Volume Data (Dalam GB) yang Diperlukan Untuk Melatih Model Bahasa Besar?
Dunia kemungkinan untuk pengenalan data ucapan dan aplikasi suara sangat besar, dan mereka digunakan di beberapa industri untuk sejumlah besar aplikasi.
Melatih model bahasa yang besar bukanlah proses satu ukuran untuk semua, terutama jika berkaitan dengan data yang dibutuhkan. Itu tergantung pada banyak hal:
- Desain modelnya.
- Pekerjaan apa yang perlu dilakukan?
- Jenis data yang Anda gunakan.
- Seberapa baik Anda ingin kinerjanya?
Yang mengatakan, LLM pelatihan biasanya membutuhkan sejumlah besar data teks. Tapi seberapa masif yang kita bicarakan? Nah, pikirkan jauh melampaui gigabyte (GB). Kami biasanya melihat terabyte (TB) atau bahkan petabyte (PB) data.
Pertimbangkan GPT-3, salah satu LLM terbesar. Hal ini dilatih pada 570 GB data teks. LLM yang lebih kecil mungkin membutuhkan lebih sedikit – mungkin 10-20 GB atau bahkan 1 GB gigabyte – tetapi masih banyak.

Tapi ini bukan hanya tentang ukuran data. Kualitas juga penting. Data harus bersih dan bervariasi untuk membantu model belajar secara efektif. Dan Anda tidak dapat melupakan bagian penting lainnya dari teka-teki tersebut, seperti daya komputasi yang Anda perlukan, algoritme yang Anda gunakan untuk pelatihan, dan penyiapan perangkat keras yang Anda miliki. Semua faktor ini memainkan peran besar dalam melatih LLM.
Bangkitnya Model Bahasa Besar: Mengapa Penting
LLM bukan lagi sekedar konsep atau eksperimen. Mereka semakin memainkan peran penting dalam lanskap digital kita. Tetapi mengapa ini terjadi? Apa yang membuat LLM ini begitu penting? Mari selami beberapa faktor kunci.
Penguasaan dalam Meniru Teks Manusia
LLM telah mengubah cara kami menangani tugas berbasis bahasa. Dibangun menggunakan algoritme pembelajaran mesin yang tangguh, model ini dilengkapi dengan kemampuan untuk memahami nuansa bahasa manusia, termasuk konteks, emosi, dan bahkan sarkasme, sampai batas tertentu. Kemampuan untuk meniru bahasa manusia ini bukanlah sesuatu yang baru, namun memiliki implikasi yang signifikan.
Kemampuan pembuatan teks lanjutan LLM dapat meningkatkan segalanya mulai dari pembuatan konten hingga interaksi layanan pelanggan.
Bayangkan bisa mengajukan pertanyaan kompleks kepada asisten digital dan mendapatkan jawaban yang tidak hanya masuk akal, tetapi juga koheren, relevan, dan disampaikan dengan nada percakapan. Itulah yang memungkinkan LLM. Mereka mendorong interaksi manusia-mesin yang lebih intuitif dan menarik, memperkaya pengalaman pengguna, dan mendemokratisasi akses ke informasi.
Daya Komputasi yang Terjangkau
Munculnya LLM tidak akan mungkin terjadi tanpa perkembangan paralel di bidang komputasi. Lebih khusus lagi, demokratisasi sumber daya komputasi telah memainkan peran penting dalam evolusi dan adopsi LLM.
Platform berbasis cloud menawarkan akses yang belum pernah ada sebelumnya ke sumber daya komputasi berkinerja tinggi. Dengan cara ini, bahkan organisasi berskala kecil dan peneliti independen dapat melatih model pembelajaran mesin yang canggih.
Selain itu, peningkatan dalam unit pemrosesan (seperti GPU dan TPU), digabungkan dengan peningkatan komputasi terdistribusi, memungkinkan untuk melatih model dengan miliaran parameter. Peningkatan aksesibilitas daya komputasi ini memungkinkan pertumbuhan dan kesuksesan LLM, yang mengarah ke lebih banyak inovasi dan aplikasi di lapangan.
Menggeser Preferensi Konsumen
Konsumen saat ini tidak hanya menginginkan jawaban; mereka menginginkan interaksi yang menarik dan dapat dihubungkan. Semakin banyak orang tumbuh menggunakan teknologi digital, terbukti bahwa kebutuhan akan teknologi yang terasa lebih alami dan mirip manusia semakin meningkat. LLM menawarkan peluang yang tak tertandingi untuk memenuhi harapan ini. Dengan menghasilkan teks mirip manusia, model ini dapat menciptakan pengalaman digital yang menarik dan dinamis, yang dapat meningkatkan kepuasan dan loyalitas pengguna. Baik itu chatbot AI yang menyediakan layanan pelanggan atau asisten suara yang menyediakan pembaruan berita, LLM mengantarkan era AI yang memahami kita dengan lebih baik.
Tambang Emas Data Tidak Terstruktur
Data tidak terstruktur, seperti email, postingan media sosial, dan ulasan pelanggan, adalah harta karun wawasan. Diperkirakan habis 80% data perusahaan tidak terstruktur dan tumbuh pada tingkat 55% per tahun. Data ini adalah tambang emas untuk bisnis jika dimanfaatkan dengan benar.
LLM berperan di sini, dengan kemampuannya untuk memproses dan memahami data tersebut dalam skala besar. Mereka dapat menangani tugas seperti analisis sentimen, klasifikasi teks, ekstraksi informasi, dan lainnya, sehingga memberikan wawasan yang berharga.
Baik itu mengidentifikasi tren dari postingan media sosial atau mengukur sentimen pelanggan dari ulasan, LLM membantu bisnis menavigasi sejumlah besar data tidak terstruktur dan membuat keputusan berdasarkan data.
Pasar NLP yang Berkembang
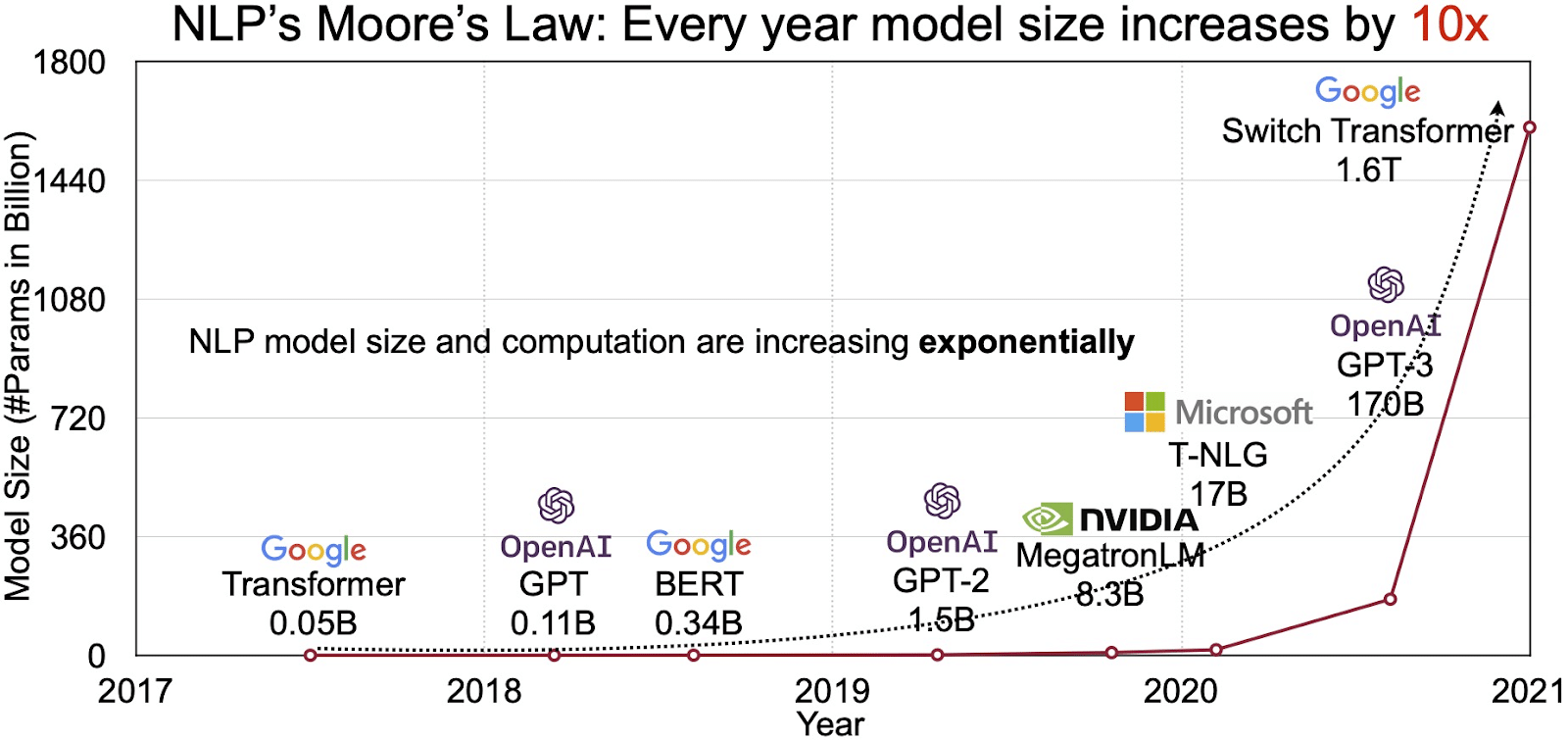
Potensi LLM tercermin dalam pasar yang berkembang pesat untuk pemrosesan bahasa alami (NLP). Analis memproyeksikan pasar NLP untuk berkembang $11 miliar pada tahun 2020 menjadi lebih dari $35 miliar pada tahun 2026. Tapi bukan hanya ukuran pasar yang berkembang. Modelnya sendiri juga berkembang, baik dalam ukuran fisik maupun jumlah parameter yang ditanganinya. Evolusi LLM selama bertahun-tahun, seperti yang terlihat pada gambar di bawah (sumber gambar: tautan), menggarisbawahi peningkatan kompleksitas dan kapasitasnya.
Kasus Penggunaan Populer Model Bahasa Besar
Berikut adalah beberapa kasus penggunaan LLM teratas dan paling umum:
- Menghasilkan Teks Bahasa Alami: Model Bahasa Besar (LLM) menggabungkan kekuatan kecerdasan buatan dan linguistik komputasi untuk menghasilkan teks secara mandiri dalam bahasa alami. Mereka dapat memenuhi beragam kebutuhan pengguna seperti menulis artikel, membuat lagu, atau terlibat dalam percakapan dengan pengguna.
- Terjemahan melalui Mesin: LLM dapat digunakan secara efektif untuk menerjemahkan teks antara setiap pasangan bahasa. Model-model ini mengeksploitasi algoritme pembelajaran mendalam seperti jaringan saraf berulang untuk memahami struktur linguistik dari bahasa sumber dan bahasa target, sehingga memfasilitasi terjemahan teks sumber ke dalam bahasa yang diinginkan.
- Membuat Konten Asli: LLM telah membuka jalan bagi mesin untuk menghasilkan konten yang kohesif dan logis. Konten ini dapat digunakan untuk membuat posting blog, artikel, dan jenis konten lainnya. Model memanfaatkan pengalaman pembelajaran mendalam mereka untuk memformat dan menyusun konten dengan cara baru dan ramah pengguna.
- Menganalisis Sentimen: Salah satu aplikasi yang menarik dari Model Bahasa Besar adalah analisis sentimen. Dalam hal ini, model dilatih untuk mengenali dan mengkategorikan keadaan emosional dan sentimen yang ada dalam teks beranotasi. Perangkat lunak ini dapat mengidentifikasi emosi seperti kepositifan, kenegatifan, netralitas, dan sentimen rumit lainnya. Ini dapat memberikan wawasan berharga tentang umpan balik dan pandangan pelanggan tentang berbagai produk dan layanan.
- Memahami, Meringkas, dan Mengklasifikasikan Teks: LLM membangun struktur yang layak untuk perangkat lunak AI untuk menafsirkan teks dan konteksnya. Dengan menginstruksikan model untuk memahami dan meneliti sejumlah besar data, LLM memungkinkan model AI untuk memahami, meringkas, dan bahkan mengkategorikan teks dalam berbagai bentuk dan pola.
- Menjawab pertanyaan: Model Bahasa Besar melengkapi sistem Penjawab Pertanyaan (QA) dengan kemampuan untuk memahami dan menanggapi permintaan bahasa alami pengguna secara akurat. Contoh populer dari kasus penggunaan ini termasuk ChatGPT dan BERT, yang memeriksa konteks kueri dan menyaring kumpulan teks yang sangat banyak untuk memberikan respons yang relevan terhadap pertanyaan pengguna.

Penandaan Part-of-Speech (POS).
Kata-kata dalam kalimat ditandai dengan fungsi tata bahasanya, seperti kata kerja, kata benda, kata sifat, dll. Proses ini membantu model dalam memahami tata bahasa dan keterkaitan antar kata.

Pengakuan Entitas Bernama (NER)
Entitas bernama seperti organisasi, lokasi, dan orang dalam kalimat ditandai. Latihan ini membantu model dalam menginterpretasikan makna semantik dari kata dan frasa dan memberikan respons yang lebih tepat.

Analisis Sentimen
Data teks diberi label sentimen seperti positif, netral, atau negatif, membantu model memahami nada emosional kalimat. Ini sangat berguna dalam menanggapi pertanyaan yang melibatkan emosi dan pendapat.
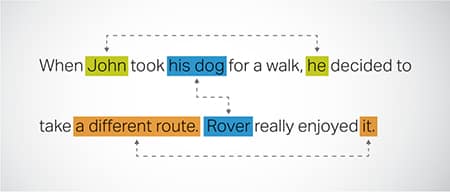
Resolusi Koreferensi
Mengidentifikasi dan menyelesaikan kasus di mana entitas yang sama dirujuk di berbagai bagian teks. Langkah ini membantu model memahami konteks kalimat, sehingga menghasilkan tanggapan yang koheren.
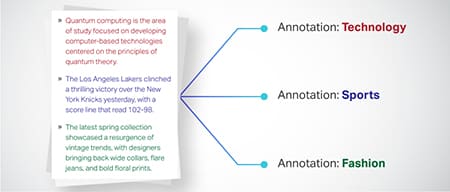
Klasifikasi Teks
Data teks dikategorikan ke dalam grup yang telah ditentukan seperti ulasan produk atau artikel berita. Ini membantu model dalam membedakan genre atau topik teks, menghasilkan tanggapan yang lebih relevan.
Persembahan Shaip
Shaip menawarkan berbagai layanan untuk membantu organisasi mengelola, menganalisis, dan memaksimalkan data mereka.
Pengikisan Web Data
Salah satu layanan utama yang ditawarkan oleh Shaip adalah pengikisan data. Ini melibatkan ekstraksi data dari URL khusus domain. Dengan memanfaatkan alat dan teknik otomatis, Shaip dapat dengan cepat dan efisien mengikis data dalam jumlah besar dari berbagai situs web, Manual Produk, Dokumentasi Teknis, forum Online, Tinjauan Online, Data Layanan Pelanggan, Dokumen Peraturan Industri, dll. Proses ini dapat sangat berharga bagi bisnis ketika mengumpulkan data yang relevan dan spesifik dari berbagai sumber.

Mesin penerjemah
Kembangkan model menggunakan kumpulan data multibahasa yang luas yang dipasangkan dengan transkripsi yang sesuai untuk menerjemahkan teks ke berbagai bahasa. Proses ini membantu membongkar hambatan linguistik dan mempromosikan aksesibilitas informasi.
Ekstraksi & Penciptaan Taksonomi
Shaip dapat membantu dengan ekstraksi dan pembuatan taksonomi. Ini melibatkan pengelompokan dan pengkategorian data ke dalam format terstruktur yang mencerminkan hubungan antara titik data yang berbeda. Ini bisa sangat berguna untuk bisnis dalam mengatur data mereka, membuatnya lebih mudah diakses dan lebih mudah untuk dianalisis. Misalnya, dalam bisnis e-niaga, data produk dapat dikategorikan berdasarkan jenis produk, merek, harga, dll., sehingga memudahkan pelanggan menelusuri katalog produk.
Pengumpulan Data
Layanan pengumpulan data kami menyediakan data dunia nyata atau sintetis penting yang diperlukan untuk melatih algoritme AI generatif dan meningkatkan akurasi dan efektivitas model Anda. Data tersebut tidak memihak, bersumber secara etis dan bertanggung jawab dengan tetap memperhatikan privasi dan keamanan data.

Tanya Jawab
Menjawab pertanyaan (QA) adalah subbidang pemrosesan bahasa alami yang berfokus pada menjawab pertanyaan secara otomatis dalam bahasa manusia. Sistem QA dilatih tentang teks dan kode yang ekstensif, memungkinkan mereka menangani berbagai jenis pertanyaan, termasuk pertanyaan faktual, definisional, dan berbasis opini. Pengetahuan domain sangat penting untuk mengembangkan model QA yang disesuaikan dengan bidang tertentu seperti dukungan pelanggan, layanan kesehatan, atau rantai pasokan. Namun, pendekatan QA generatif memungkinkan model menghasilkan teks tanpa pengetahuan domain, hanya mengandalkan konteks.
Tim spesialis kami dapat dengan cermat mempelajari dokumen atau manual komprehensif untuk menghasilkan pasangan Tanya-Jawab, memfasilitasi pembuatan AI Generatif untuk bisnis. Pendekatan ini dapat secara efektif menangani pertanyaan pengguna dengan menambang informasi terkait dari korpus yang luas. Pakar tersertifikasi kami memastikan produksi pasangan Tanya Jawab berkualitas terbaik yang menjangkau beragam topik dan domain.

Peringkasan Teks
Pakar kami mampu menyaring percakapan yang komprehensif atau dialog yang panjang, memberikan ringkasan yang ringkas dan berwawasan luas dari data teks yang ekstensif.

Generasi Teks
Latih model menggunakan kumpulan data teks yang luas dalam berbagai gaya, seperti artikel berita, fiksi, dan puisi. Model ini kemudian dapat menghasilkan berbagai jenis konten, termasuk berita, entri blog, atau postingan media sosial, menawarkan solusi hemat biaya dan hemat waktu untuk pembuatan konten.
Speech Recognition
Kembangkan model yang mampu memahami bahasa lisan untuk berbagai aplikasi. Ini termasuk asisten yang diaktifkan suara, perangkat lunak dikte, dan alat terjemahan waktu nyata. Prosesnya melibatkan penggunaan kumpulan data komprehensif yang terdiri dari rekaman audio bahasa lisan, dipasangkan dengan transkrip yang sesuai.

Rekomendasi Produk
Kembangkan model dengan menggunakan kumpulan data riwayat pembelian pelanggan yang ekstensif, termasuk label yang menunjukkan produk yang cenderung dibeli oleh pelanggan. Tujuannya adalah untuk memberikan saran yang tepat kepada pelanggan, sehingga meningkatkan penjualan dan meningkatkan kepuasan pelanggan.
Keterangan Gambar
Merevolusi proses interpretasi gambar Anda dengan layanan Image Captioning kami yang canggih dan digerakkan oleh AI. Kami menanamkan vitalitas ke dalam gambar dengan menghasilkan deskripsi yang akurat dan bermakna secara kontekstual. Ini membuka jalan bagi keterlibatan inovatif dan kemungkinan interaksi dengan konten visual Anda untuk audiens Anda.

Pelatihan Layanan Text-to-Speech
Kami menyediakan kumpulan data ekstensif yang terdiri dari rekaman audio ucapan manusia, ideal untuk melatih model AI. Model ini mampu menghasilkan suara yang natural dan menarik untuk aplikasi Anda, sehingga memberikan pengalaman suara yang khas dan imersif bagi pengguna Anda.



