Pengenalan ucapan otomatis (ASR) telah berkembang pesat. Meskipun telah ditemukan sejak lama, itu hampir tidak pernah digunakan oleh siapa pun. Namun, waktu dan teknologi kini telah berubah secara signifikan. Transkripsi audio telah berkembang secara substansial.
Teknologi seperti AI (Kecerdasan Buatan) telah mendukung proses terjemahan audio-ke-teks untuk hasil yang cepat dan akurat. Akibatnya, aplikasinya di dunia nyata juga meningkat, dengan beberapa aplikasi populer seperti Tik Tok, Spotify, dan Zoom menyematkan proses tersebut ke dalam aplikasi seluler mereka.
Jadi, mari kita jelajahi ASR dan temukan mengapa ini adalah salah satu teknologi paling populer di tahun 2022.
Apa itu pidato ke teks?
Speech to text adalah teknologi yang disempurnakan dengan AI yang menerjemahkan ucapan manusia dari analog ke bentuk digital. Selanjutnya, bentuk digital dari data yang dikumpulkan ditranskripsikan ke dalam format teks.
Pidato ke teks sering dikacaukan dengan pengenalan suara yang sama sekali berbeda dari metode ini. Dalam pengenalan suara, fokusnya adalah mengidentifikasi pola suara orang, sedangkan dalam metode ini, sistem mencoba mengidentifikasi kata-kata yang diucapkan.
Nama Umum Ucapan ke Teks
Teknologi pengenalan suara canggih ini juga populer dan disebut dengan nama:
- Pengenalan ucapan otomatis (ASR)
- Pengenalan suara
- Pengenalan suara komputer
- Transkripsi audio
- Pembacaan Layar
Memahami Cara Kerja Pengenalan Ucapan Otomatis
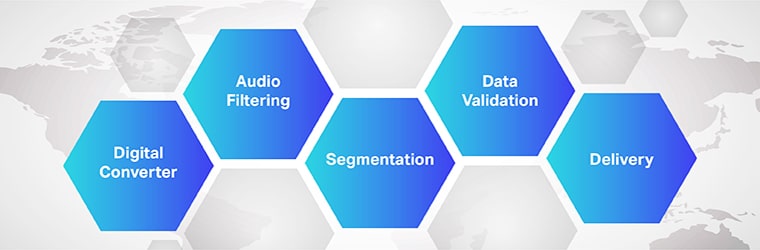
Cara kerja perangkat lunak terjemahan audio-ke-teks itu rumit dan melibatkan penerapan beberapa langkah. Seperti yang kita ketahui, speech-to-text adalah perangkat lunak eksklusif yang dirancang untuk mengubah file audio menjadi format teks yang dapat diedit; ia melakukannya dengan memanfaatkan pengenalan suara.
Proses
- Awalnya, menggunakan konverter analog-ke-digital, program komputer menerapkan algoritme linguistik ke data yang disediakan untuk membedakan getaran dari sinyal pendengaran.
- Selanjutnya, suara yang relevan disaring dengan mengukur gelombang suara.
- Selanjutnya, suara didistribusikan / tersegmentasi ke dalam seperseratus atau seperseribu detik dan dicocokkan dengan fonem (Satuan suara yang dapat diukur untuk membedakan satu kata dari kata lain).
- Fonem selanjutnya dijalankan melalui model matematika untuk membandingkan data yang ada dengan kata, kalimat, dan frasa yang sudah dikenal.
- Outputnya berupa teks atau file audio berbasis komputer.
[Baca juga: Tinjauan Komprehensif tentang Pengenalan Ucapan Otomatis]

Apa Kegunaan Speech to Text?
Ada beberapa penggunaan perangkat lunak pengenalan suara otomatis, seperti:
- Pencarian Konten: Sebagian besar dari kita telah beralih dari mengetik huruf di ponsel menjadi menekan tombol perangkat lunak untuk mengenali suara kita dan memberikan hasil yang diinginkan.
- Layanan Pelanggan: Chatbots dan asisten AI yang dapat memandu pelanggan melalui beberapa langkah awal proses telah menjadi umum.
- Teks Tertutup Waktu Nyata: Dengan peningkatan akses global ke konten, teks tertutup secara real-time telah menjadi pasar yang menonjol dan signifikan, mendorong ASR maju untuk penggunaannya.
- Dokumentasi Elektronik: Beberapa departemen administrasi telah mulai menggunakan ASR untuk memenuhi tujuan dokumentasi, melayani kecepatan dan efisiensi yang lebih baik.
Apa Tantangan Utama untuk Pengenalan Ucapan?
Anotasi audio belum mencapai puncak perkembangannya. Masih banyak tantangan yang coba dilawan oleh para insinyur untuk membuat sistem menjadi efisien, seperti
- Mendapatkan kontrol atas aksen dan dialek.
- Memahami konteks kalimat yang diucapkan.
- Pemisahan kebisingan latar belakang untuk memperkuat kualitas input.
- Mengalihkan kode ke bahasa yang berbeda untuk pemrosesan yang efisien.
- Menganalisis isyarat visual yang digunakan dalam pidato dalam kasus file video.
Transkripsi Audio dan Pengembangan AI Speech-to-Text
Tantangan terbesar dengan software Automatic Speech Recognition adalah membuat outputnya 100% akurat. Karena data mentah bersifat dinamis dan satu algoritme tidak dapat diterapkan, data tersebut dianotasi untuk melatih AI agar memahaminya dalam konteks yang tepat.
Untuk melakukan proses ini, tugas-tugas khusus harus dilaksanakan, seperti:
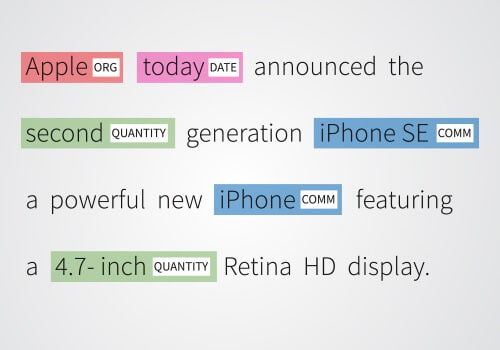 Pengakuan Entitas Bernama (NER): APM adalah proses mengidentifikasi dan mengelompokkan entitas bernama berbeda ke dalam kategori tertentu.
Pengakuan Entitas Bernama (NER): APM adalah proses mengidentifikasi dan mengelompokkan entitas bernama berbeda ke dalam kategori tertentu.- Analisis Sentimen & Topik: Perangkat lunak yang menggunakan beberapa algoritme melakukan analisis sentimen dari data yang disediakan untuk memberikan hasil yang bebas kesalahan.
- Analisis Niat & Percakapan: Deteksi niat bertujuan untuk melatih AI untuk mengenali niat pembicara. Ini terutama digunakan untuk membuat chatbot bertenaga AI.
Kesimpulan
Teknologi ucapan-ke-teks berada pada tahap yang hebat saat ini. Dengan semakin banyaknya perangkat digital yang menggabungkan pencarian suara dan asisten kontrol ke dalam aplikasi mereka, permintaan transkripsi audio akan meningkat. Jika Anda ingin menambahkan fitur yang mengesankan ini ke aplikasi Anda, hubungi pakar pengumpulan data ucapan Shaip untuk mengetahui detail lengkapnya.


