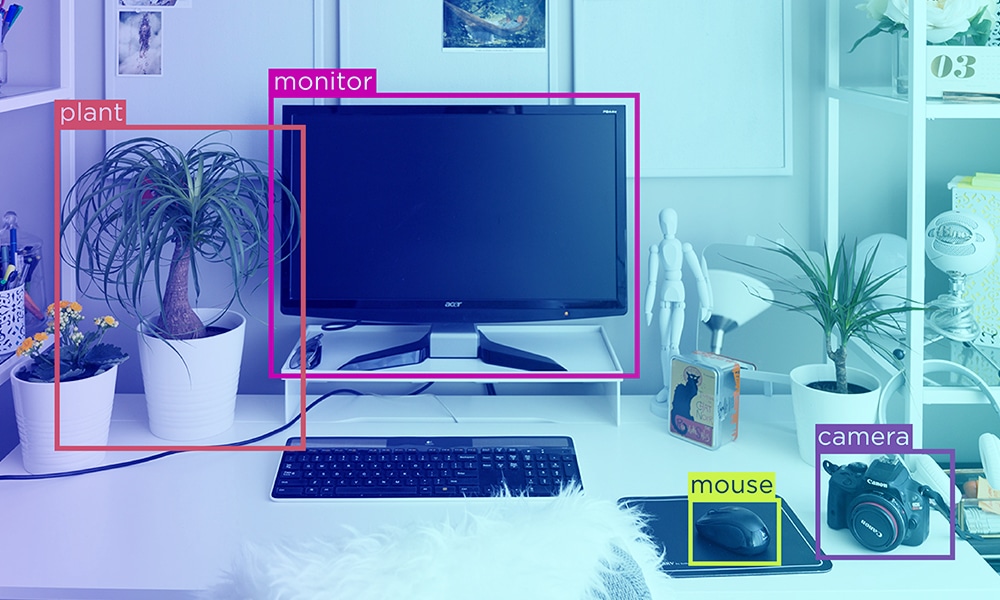
Data adalah kekuatan super yang mengubah lanskap digital di dunia saat ini. Dari email hingga postingan media sosial, ada data di mana-mana. Memang benar bahwa bisnis tidak pernah memiliki akses ke begitu banyak data, tetapi apakah cukup memiliki akses ke data? Sumber informasi yang kaya menjadi tidak berguna atau usang ketika tidak diproses.
Teks yang tidak terstruktur dapat menjadi sumber informasi yang kaya, tetapi tidak akan berguna bagi bisnis kecuali datanya diatur, dikategorikan, dan dianalisis. Data tidak terstruktur, seperti teks, audio, video, dan media sosial, berjumlah 80 -90% dari semua data. Selain itu, hampir 18% organisasi dilaporkan memanfaatkan data tidak terstruktur organisasi mereka.
Memilah secara manual terabyte data yang disimpan di server adalah tugas yang memakan waktu dan terus terang mustahil. Namun, dengan kemajuan dalam pembelajaran mesin, pemrosesan bahasa alami, dan otomatisasi, struktur dan analisis data teks dapat dilakukan dengan cepat dan efektif. Langkah pertama dalam analisis data adalah klasifikasi teks.
Apa itu Klasifikasi Teks?
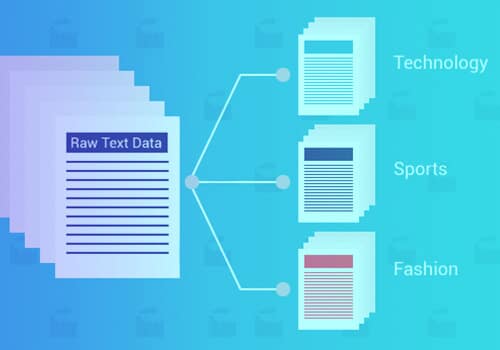
Klasifikasi atau kategorisasi teks adalah proses pengelompokan teks ke dalam kategori atau kelas yang telah ditentukan. Dengan menggunakan pendekatan pembelajaran mesin ini, apa saja teks – dokumen, file web, studi, dokumen hukum, laporan medis, dan banyak lagi - Dapat diklasifikasikan, diatur, dan terstruktur.
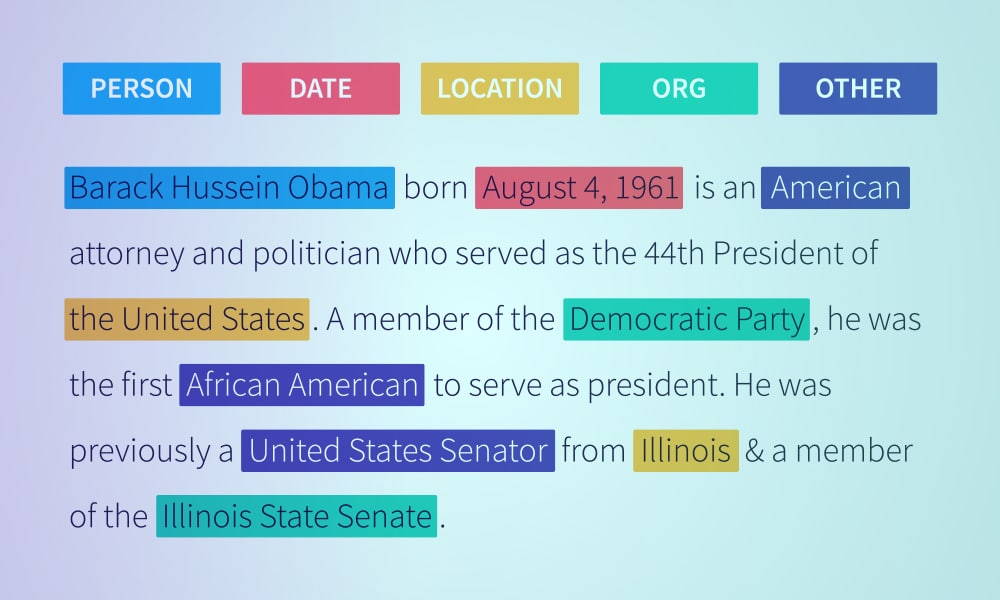
Klasifikasi teks adalah langkah dasar dalam pemrosesan bahasa alami yang memiliki beberapa kegunaan dalam deteksi spam. Analisis sentimen, deteksi niat, pelabelan data, dan lainnya.
Kemungkinan Penggunaan Kasus Klasifikasi Teks
 Ada beberapa manfaat menggunakan klasifikasi teks pembelajaran mesin, seperti skalabilitas, kecepatan analisis, konsistensi, dan kemampuan untuk membuat keputusan cepat berdasarkan percakapan waktu nyata.
Ada beberapa manfaat menggunakan klasifikasi teks pembelajaran mesin, seperti skalabilitas, kecepatan analisis, konsistensi, dan kemampuan untuk membuat keputusan cepat berdasarkan percakapan waktu nyata.
Saat model ML dilatih menggunakan AI yang secara otomatis mengkategorikan item dalam kategori yang telah ditentukan sebelumnya, Anda dapat dengan cepat mengonversi browser biasa menjadi pelanggan.
Proses Klasifikasi Teks
Proses klasifikasi teks dimulai dengan pra-pemrosesan, pemilihan fitur, ekstraksi, dan pengklasifikasian data.

Pra-Pemrosesan
Tokenisasi: Teks dipecah menjadi bentuk teks yang lebih kecil dan lebih sederhana untuk memudahkan klasifikasi.
Normalisasi: Semua teks dalam dokumen harus memiliki tingkat pemahaman yang sama. Beberapa bentuk normalisasi antara lain,
- Mempertahankan standar gramatikal atau struktural di seluruh teks, seperti penghapusan spasi atau tanda baca. Atau mempertahankan huruf kecil di seluruh teks.
- Menghapus awalan dan sufiks dari kata-kata dan membawanya kembali ke kata dasarnya.
- Menghilangkan stopwords seperti 'and' 'is' 'the' dan lainnya yang tidak menambah nilai pada teks.
Pemilihan Fitur
Pemilihan fitur adalah langkah mendasar dalam klasifikasi teks. Proses ini ditujukan untuk merepresentasikan teks dengan fitur yang paling relevan. Pilihan fitur membantu menghapus data yang tidak relevan, dan meningkatkan akurasi.
Pemilihan fitur mengurangi variabel input ke dalam model dengan hanya menggunakan data yang paling relevan dan menghilangkan noise. Berdasarkan jenis solusi yang Anda cari, model AI Anda dapat dirancang untuk hanya memilih fitur yang relevan dari teks.
Ekstraksi Fitur
Ekstraksi fitur adalah langkah opsional yang dilakukan beberapa bisnis untuk mengekstraksi fitur kunci tambahan dalam data. Ekstraksi fitur menggunakan beberapa teknik, seperti mapping, filtering, dan clustering. Manfaat utama menggunakan ekstraksi fitur adalah – ini membantu menghapus data yang berlebihan dan meningkatkan kecepatan pengembangan model ML.
Menandai Data ke Kategori yang Telah Ditentukan
Memberi tag teks ke kategori yang telah ditentukan adalah langkah terakhir dalam klasifikasi teks. Dapat dilakukan dengan tiga cara berbeda,
- Penandaan Manual
- Pencocokan Berbasis Aturan
- Algoritma Pembelajaran – Algoritme pembelajaran selanjutnya dapat diklasifikasikan menjadi dua kategori seperti pemberian tag yang diawasi dan pemberian tag yang tidak diawasi.
- Pembelajaran yang diawasi: Model ML dapat menyelaraskan tag secara otomatis dengan data yang dikategorikan yang ada dalam pemberian tag yang diawasi. Saat data yang dikategorikan sudah tersedia, algoritme ML dapat memetakan fungsi antara tag dan teks.
- Pembelajaran tanpa pengawasan: Itu terjadi ketika ada kelangkaan data yang ditandai sebelumnya. Model ML menggunakan algoritme pengelompokan dan berbasis aturan untuk mengelompokkan teks serupa, seperti berdasarkan riwayat pembelian produk, ulasan, detail pribadi, dan tiket. Kelompok besar ini dapat dianalisis lebih lanjut untuk menarik wawasan khusus pelanggan yang berharga yang dapat digunakan untuk merancang pendekatan pelanggan yang disesuaikan.
Ada beberapa kasus penggunaan untuk klasifikasi teks di berbagai industri. Meskipun mengumpulkan, mengelompokkan, mengklasifikasikan, dan mengekstraksi wawasan berharga dari data teks selalu digunakan di beberapa bidang, klasifikasi teks menemukan potensinya dalam pemasaran, pengembangan produk, layanan pelanggan, manajemen, dan administrasi. Ini membantu bisnis mendapatkan intelijen kompetitif, pengetahuan pasar dan pelanggan, dan membuat keputusan bisnis yang didukung data.
Mengembangkan alat klasifikasi teks yang efektif dan berwawasan tidaklah mudah. Namun, dengan Shaip sebagai mitra data Anda, Anda dapat mengembangkan alat klasifikasi teks berbasis AI yang efektif, dapat diskalakan, dan hemat biaya. Kami punya banyak dataset yang dianotasi secara akurat dan siap digunakan yang dapat disesuaikan untuk kebutuhan unik model Anda. Kami mengubah teks Anda menjadi keunggulan kompetitif; hubungi hari ini.